Optimizing for Free Hosting — Elixir Deployments

Another way to deploy Elixir apps
There are A LOT of different ways to deploy Elixir/Phoenix applications. I want to fill a gap in the current literature: how do you deploy a Phoenix web app to a single Linux server optimizing for cost effectiveness, control, and simplicity, while using modern Elixir tools like releases to achieve zero-downtime deploys without hot code upgrading?
I’m going to walk through a deployment strategy that can take you start-to-finish with a full-featured Phoenix web app running on a free-forever Google Cloud Platform Compute Engine instance.
This setup is completely free, and when you have more traffic the cost of scaling on raw GCP instances is a lot cheaper than on platform-as-a-service offerings (Heroku, Gigalixir, Render, Fly, etc). And, you’re in full control of the system so you don’t have to work around any fixed limitations. Scaling can be as simple as upgrading the specs of the instance when it can’t keep up anymore.
My heretical belief is that the biggest risk to the reliability / availability of your app is developers changing code and running tasks, NOT the remote chance of hardware failure. Don’t be dumb — back up your database. But otherwise, the biggest way to reduce infrastructure-related downtime is keeping your server environment and deployment processes dead simple and fast so that devs won’t make mistakes and can restore things quickly when they do.
One of the great things about Elixir and Phoenix is that you can get a LOT of milage out of very limited hardware, so there’s a good chance that your hosting with this strategy will stay free for a very long time, and incredibly cheap for even longer. And it will be wicked fast, reliable, and observable.
What we’re optimizing for
- Absolutely 100% free to start, cheap to scale
- No Docker, Ansible, Distillery, or other build/deploy tools
- Pure Elixir — no Nginx or external dependencies (since the pure-elixir approach is still a bit new, you can read the same guide but using an Nginx setup here)
- Single server setup
- Fault-tolerant at server level, e.g. if the server crashes or restarts the app will come back up automatically
- Secure (enough, this can be an infinite rabbit hole)
- Fast no-downtime deployments and rollbacks, without hot code reloading
- Full control and visibility, leveraging raw Linux built-in tools
Free without the compromises (except your time of course)
I really like the level of control and flexibility that this approach provides. You’ll end up feeling a lot more comfortable with the basics of how your server runs and how to hook in and introspect when there are problems. It takes some time to set up, and there might be some new Linux skills that you’ll need to pick up along the way. This is a long guide, but stick with me and I think you’ll be really happy with the result! (or bookmark it and come back the next time you need to spin up a side project)
Overview
This is a quick outline of what we’ll be doing, so you can decide if it looks interesting before we get into the weeds.
- Get a domain
- Log into Google Cloud Platform and provision an E2-Micro Compute Engine instance
- Make the IP address of the instance static
- Add your SSH key to metadata in Compute Engine settings so you can connect to the instance
- Set up an ssh alias on your dev machine so it’s easy to access the server
- Enable swap memory on the instance
- Install Erlang, Elixir, Node, and Postgres
- Set a secure password for Postgres
- Configure Postgres to allow remote connections
- Connect to your remote Git repo where your project lives
- Get your app secrets onto the server
- Configure SSL with SiteEncrypt
- Forward ports 80 and 443 to the ones the app will listen on
- Build a deployment shell script for some basic CI checks and allowing incremental release versions and no-downtime deployments
- Create systemd services to ensure app starts up if server crashes or resets
- Commit and push a change. Then deploy using a single command on your dev machine!
- Attach to journald to watch logs
- Bonus 1: Secure your data against the possibility of eventual hardware failure by creating another Google account with a free instance and set up automated backups using cron
- Bonus 2: Rollback script
The Details!
1 — Get a domain
If you want this whole thing to be super free, you can get a domain from https://freenom.com and get a full-fledged domain with DNS and the works for free. The downside is that you’re limited to one of five super random top level domains (.ml, .gq etc), but it’s a great way to get the name you want before committing the cash to buy the .com version. Once you have a domain, go to the DNS settings page — we’ll be adding some records later on.
2 — Provision an E2-Micro Compute Engine instance
You can access the Google Cloud Platform console using any Google account you own (typically a Gmail address). For the sake of separation (and security), I like to create a new gmail address with the name of my project in it so that the account is fully isolated (e.g. damon.my.app@gmail.com).
If you access the console with a new account, you may need to activate the free trial before it will let you do much. Go ahead and activate it, and put in a card if prompted. Don’t worry — you won’t be charged for this server even after the trial runs out.
Once you’re in the console, click on the top-left menu icon and then select Compute Engine -> VM Instances. If it’s your first time, it may take a minute to start. When it’s ready, click the “Create” button. Configure with the following options and then create:
Name: whatever you want
Region: double check https://cloud.google.com/free to make sure the region you want is listed in the Compute Engine section
Series: E2
Machine Type: e2-micro
Boot Disk:
Operating System: Ubuntu
Version: Ubuntu 22.04 LTS (x86/64)
Boot Disk Type: Standard persistent disk, 30GB
Firewall: allow both HTTP and HTTPS trafficNOTE: If you followed this guide before August 19th, 2021, you’ll need to update the instance type of your Google Cloud server to keep it free. You have an “F1-micro” type, and you need to change it to a “E2-micro” type. Learn how to do that here.
3 — Make the IP address of the instance static
Click the triple lines icon in the top left to bring up the menu, then go to VPC Network -> IP addresses. There should be a single row with an “Access Type” of “External”, belonging to the instance you just created. Click the “RESERVE” button on the row to make the IP address static (otherwise it could change at any time). Copy the IP address (should look something like 34.69.61.31), since you’ll need it in the next steps.
In the DNS settings for your domain, create A records for both <your_domain>.com and www.<your_domain>.com that point to that IP address.
4 — Add your SSH key
Click the triple lines icon again in the top left and go to Compute Engine -> Metadata (under the Settings header). Click on the tab SSH Keys. Then click the “Add SSH Keys” button.
To get an SSH key from your dev machine to paste into the field, run cat ~/.ssh/id_rsa.pub in your local terminal. If you don’t get output, create an ssh key by following these instructions and then run the command again and paste the result into the field in GCP and hit “Save”.
5 — Set up SSH alias
To connect to the server, we could run ssh <IP Address from step 3>, but it’s going to get tiresome to type in the IP all the time (especially if you have lots of these servers). So instead, we’ll set up an alias so that we can type in ssh my_app and have it connect automatically.
On your dev machine, enter vim ~/.ssh/config (which will create or open the file). Put the following code in the file, making sure that the first block goes at the very top before anything else already in there, and that the second block goes at the very bottom below anything else:
Host my_app
Hostname <IP address from step 3>
User <your local user name>Host *
AddKeysToAgent yes
UseKeychain yes
IdentityFile ~/.ssh/id_rsa
Note: if you aren’t familiar with
vim, just use the arrow keys to navigate and learn how to switch between insert mode and command mode, and saving and exiting.
Replace the IP and user with your info and remove the comments. Save and quit, and now you should be able to connect to your server with the command ssh my_app. Nice! If you connect successfully to the instance, congrats! You’re now connected and in full control of your free server. If you didn’t connect successfully, you may need to look up how to add your ssh key to ssh-agent.
When you added your key to the metadata, a Linux user account was created on the server that matches the name of your local user account. This user has sudo privileges, isn’t the root user, and is passwordless (can only be accessed with the SSH keys in metadata), all of which make this user a pretty good choice for the user account responsible for deploying the app. Assuming you’re the only developer deploying code for now this setup is plenty secure, but as you add developers and complexity you might think about creating a dedicated user for deployment with more restricted permissions.
6 — Enable swap memory on the instance
This server is TINY — it only has 1GB of RAM. When you compile a Phoenix application on it for the first time on it, there’s a good chance that it will freeze up on you by running out of resources. But, since we get a 30GB spinner hard drive (HDD) for free along with it, we can safely enable swap memory which will allow the server to push past the limit (albeit with slower memory) once it exceeds available RAM. To create 1GB of swap space, run the following on the server:
sudo fallocate -l 1G /swapfileNext make sure the file can only be read by the root user:
sudo chmod 600 /swapfileNext we’ll mark the file as swap:
sudo mkswap /swapfileAnd enable it:
sudo swapon /swapfileAnd make it permanent to survive restarts:
echo '/swapfile none swap sw 0 0' | sudo tee -a /etc/fstabTo verify that it worked, run the handy command top which will give you a little dashboard of the resource consumption on the server. You should see a line like the following: MiB Swap: 1024.0 total. Press ctrl+c to exit.
There is a lot to learn about swap, and if you want to read more you can start here. These commands and the default configuration that comes with them are fine for our purposes here.
7 — Install Erlang, Elixir, Node, and Postgres
First Postgres:
sudo apt install postgresql postgresql-contribIn case these instructions get stale, follow the official Elixir install guide for Ubuntu here. Install Erlang and Elixir using the following:
wget https://packages.erlang-solutions.com/erlang-solutions_2.0_all.deb && sudo dpkg -i erlang-solutions_2.0_all.debsudo apt updatesudo apt install esl-erlangsudo apt install elixir
NOTE: as of this writing (March 31, 2023) the preceding commands will give you Elixir 1.13, or may not work at all. What you WANT though is Elixir 1.14 (so that the latest version of Phoenix, 1.7, works properly), which currently is only available with version managers or installing from a precompiled package. If you run the commands above and get Elixir 1.14, you can ignore this because it means apt was updated to use the newer Elixir version. If you get 1.13, run sudo apt remove elixir and then use a version manager or precompiled package to install 1.14 (I would recommend asdf). Setting it up is a lot of work, but it gives you really granular control over the versions). Here is a quick start for setting up Erlang/Elixir with asdf:
- Run
git clone https://github.com/asdf-branch v0.11.3 - Add the following two lines to the very top of your
~/.bashrcfile:."$HOME/.asdf/asdf.sh"and this one:."$HOME/.asdf/completions/asdf.bash" - Run
sudo apt install dirmngr gpg curl gawk build-essential libssl-dev automake libncurses5-dev unzipwhich will get a bunch of required dependencies - Run
asdf plugin add erlang https://github.com/asdf-vm/asdf-erlang.gitwhich will add theerlangplugin - Run
asdf install erlang 25.3(this will take an extremely long time, be patient) - Run
asdf global erlang 25.3 - Run
asdf plugin-add elixir https://github.com/asdf-vm/asdf-elixir.gitwhich will add theelixirplugin - Run
asdf install elixir 1.14.3-otp-25(wow this is so much faster than Erlang!!) - Run
asdf global elixir 1.14.3-otp-25 - To confirm it all worked run
elixir -vand you should see1.14.3in the output. Whew!
8 — Set a secure password for Postgres
Now that Postgres is installed, we’ll want to change the password to something secure. Later, we’ll be opening the database port on the server to the web (alert: security tradeoff!), so the password has to be rock solid. Generate a random password with a tool like https://passwordsgenerator.net and paste it into a safe place. Log into Postgres with the default postgres user:
sudo -u postgres psqlAnd update the password:
\password postgres(paste the password you generated and hit enter)(now put \q and hit enter to quit)
9 — Configure Postgres to allow remote connections
It’s often helpful to be able to access your database with a GUI on your development machine. I use Postico, but TablePlus and pgAdmin work great too. But before you can use one of these to connect to your database, you’ll need to adjust the firewall in GCP and alter some Postgres settings to open the database port (5432) to the outside world.
Back in the GCP console, open the navigation menu and go to VPC network -> Firewall. Click the “Create Firewall Rule” button up top. Alter the following settings and click “Create”:
Name: whatever you want, something like "database"
Targets: All instances in the network
Source IP Ranges: 0.0.0.0/0
tcp: Check box, and enter 5432 in fieldSecurity note: the more secure way to open the firewall is to restrict the Targets to just your instance so you don’t add instances later without remembering the port is open by default on all of them now. Also you could restrict the Source IP Ranges to just your own IP or the IP of a VPN that you can access, so that the port is only open to you (instead of the whole internet). However, if your Postgres password is secure and your database doesn’t hold extremely sensitive data, this configuration will probably be fine till you’re ready to really tighten security as you scale.
Now, back on the server, we’ll open up the Postgres server itself to allow connections beyondlocalhost. Find your postgresql.conf file by running:
sudo find / -name "postgresql.conf"Mine is at /etc/postgresql/14/main/postgresql.conf
Open the file to edit it:
sudo vim <the file path you found>Replace the line # listen_addresses = 'localhost' with listen_addresses = '*'.
Find your pg_hba.conf file using sudo find / -name "pg_hba.conf" (mine is /etc/postgresql/14/main/pg_hba.conf) and open to edit:
sudo vim <the file path you found>Add the following lines at the very end of the file:
host all all 0.0.0.0/0 md5
host all all ::/0 md5Now, restart postgres: sudo systemctl restart postgresql
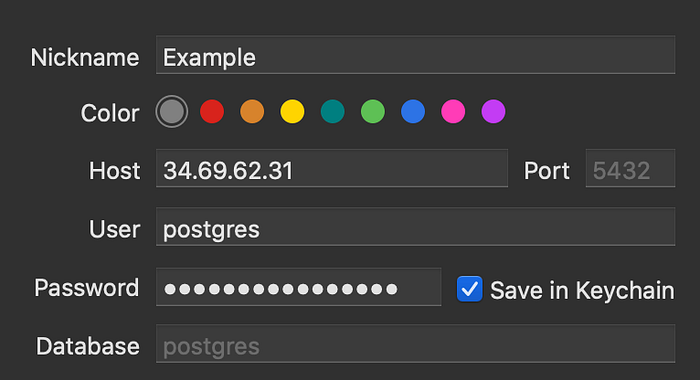
Verify that you can connect with Postico or whatever app you use. Here’s an example of what it should look like. This will connect you to the postgres database which doesn’t have anything in it which is fine. Later, we’ll run MIX_ENV=prod mix ecto.create to actually create the DB for our app, and we’ll tweak these settings in Postico so we can connect to that specific database.
10 — Connect to your remote Git repo where your project lives
Finally, we’re ready to put some code on this server! I’ve created an empty Phoenix repository on GitHub that you’re welcome to fork and follow along. All of the examples from here on out will use the project name my_app, so make sure to replace it anywhere it shows up with your own project name if you’re not forking and following along. To see the finished version of the code from this article, you can look at this small pull request to the empty app.
Once you’ve forked the project, on your server run the following:
git clone https://github.com/<YOUR_GITHUB_USERNAME>/my_appNote: your fork will be a public repo so there aren’t any authentication considerations, but if you’re using a private repo you’ll want to generate an SSH key on the server and add it to your user account in GitHub, BitBucket, or wherever the repo lives. Then, make sure to run the
git clonecommand using ssh, otherwise you’ll be prompted for account credentials every time you deploy and it’ll interrupt the smooth deployment process we’ll be setting up later.
Now, on your dev machine, open up the project (if you’re using the example repo fork just git clone it locally). We’re going to be creating a config/prod.secret.exs file and putting actual secrets in it, so we need to do some cleanup to make sure those secrets don’t get saved in our source control (git). So first, add the following lines to the end of your .gitignore:
# Ignore secrets files
/config/*.secret.exs# Ignore local cert files
/tmp/
You’ll also need to add the following line at the end of config/prod.exs:
import_config "prod.secret.exs"And remove everything but the following from config/runtime.exs:
import ConfigCommit and push those changes, then create a blank file config/prod.secret.exs. We need some database credentials and some endpoint instructions to start the server with a dynamic port. You can use the following, but be sure to generate a secret_key_base and paste in your prod database password that you generated in step 8.
11 — Get your prod secrets onto the server
The next step is to move the prod.secret.exs file that you just created up to the server, using scp (which stands for “secure copy”). It works just like the ssh my_app command that we use to connect to the server, but you specify a local path and a remote path and it will transfer files up to the server (or down from the server). Close the SSH session to the server by typing exit, and enter the following in your local shell:
scp config/prod.secret.exs my_app:~/my_app/config/Now connect to the server again with ssh my_app, and cd into the my_app directory. Let’s make sure that our config between the app and database is successful by running the following:
MIX_ENV=prod mix deps.getMIX_ENV=prod mix ecto.create
It may take a few minutes compiling this first time (remember, the VM is VERY small). Once it’s done though, sweet! You’ve got a database. Make sure to update your local Postico config (see step 9) with the database name, my_app in this case, and make sure you can connect.
12 — Configure SSL with SiteEncrypt
You absolutely need to secure your website, using SSL. And, the Elixir SiteEncrypt library which uses the Let’s Encrypt project makes it free and straightforward to set up. We’re going to get a Let’s Encrypt cert using only Elixir.
We’re going to follow most of the setup instructions from the README of the SiteEncrypt library, but because we’re using the config/prod.secret.exs file for secrets instead of environment variables we’re going to change a couple of things from those instructions.
Open your project locally, and add the following to your deps in mix.exs:
{:site_encrypt, "~> 0.5"}Next, open your lib/my_app_web/endpoint.ex file and add the following to the top of the file (making sure to add your own domain and email address):
Next, open up lib/application.ex and replace the line MyAppWeb.Endpoint with the line {SiteEncrypt.Phoenix, MyAppWeb.Endpoint}.
Next, open config/dev.exs and put the line https: [port: 4001], beneath the http line. This change allows you to go to localhost:4001 when running the app locally so you can have SSL encryption even when developing.
Next, do the same thing in config/test.exs: put the line https: [port: 4001], beneath the http line (your tests won’t run unless you have https config now)
Next, replace the MyAppWeb.Endpoint section of your config/prod.exs with the following, which is just some config to enable strong security and setting the path for the certificates in production (remember to replace the placeholders with your domain and username):
One last change that Site Encrypt doesn’t explicitly tell us to do: open lib/my_app_web/endpoint.ex again and add a quick function plug so that all requests with a www get redirected to the main url. Add the function definition and plug call after the couple of socket calls already there, and before the plug calls already there:
Commit those changes and push them up!
13 — Forward ports
Before we can test that these changes worked, we need to make sure that our app is accessible to the internet. We’ll be running the app on port 4000, but since regular web requests come in on port 80 we’ll need to forward them over to 4000.
Our zero downtime deployment strategy is to spin up our app with the new version of the code, while the old version of the code is still running but on a separate port (
4000or4001). Then, we switch the forwarding so that it starts directing requests to the port where the new code is running.
To do the forwarding, we’re going to use the built-in package iptables, which has a lot of complicated options and features and if you want to learn more about it you should do some googling. For now, you can trust that these magic commands below will tell the system to forward port 80 to 4000, and port 443 (the SSL port) to 4040 where our app is listening. Get back on the server with ssh my_app and then run the following:
sudo iptables -t nat -A PREROUTING -p tcp --dport 80 -j REDIRECT --to-port 4000
sudo iptables -t nat -A PREROUTING -p tcp --dport 443 -j REDIRECT --to-port 4040Now let’s install a package that will make sure those rules stick around even if our server is rebooted:
sudo apt install iptables-persistentWhen prompted, select “yes” and “yes” to save the current rules.
The “magic commands” that create port forwarding rules will show up later with a
-Roption instead of-A, which stand for “Replace” and “Append” respectively. Using the same command but with the Replace option is how we will switch from port4000to4001and from port4040to4041which will instantly cut requests over from the old running version of the app to the new running version, without downtime.
Next, cd into the my_app directory and run git pull to get the changes that you made locally.
Now, let’s get Phoenix up and running (don’t worry, more robust deployment is coming) and make sure that requests are being forwarded successfully:
# get the new deps
MIX_ENV=prod mix deps.get# get the assets ready
MIX_ENV=prod mix assets.deploy# run the app on port 4000 and 4040
MIX_ENV=prod mix phx.server
Now visit <your_domain>.com and you should see the Phoenix page. Very cool!
14 — Build a deployment shell script
Now that you have an app running on your custom domain, with a database and SSL, you could decide that it’s good enough and find a quick hack to keep it running, like running Phoenix in the background or manually deploying releases.
I’m begging you though to stay with me and not try to take a shortcut, because you’ll end up wasting a lot of time fiddling with things. You’ll have to manually start and stop the system, think about database migrations, and you won’t get zero downtime deployments. It’s brittle and if the server ever restarts automatically for required maintenance, your app won’t come back up by itself.
We’re going to use a simple but powerful tool as the main way to automate and streamline most of the deployment process: the lowly bash script. bash is far from being the most beautiful and expressive scripting language. But, it’s a pragmatic choice because it’s the default for terminal shells and so you can copy and paste parts of scripts in your shell to manually run things. And getting better at bash will improve your skills on the command line which will make you a more capable server administrator.
On the server, cd to your home directory (cd ~/ or even just cd), and then create a deploy.sh file:
vim deploy.shWe’ll build this file section by section to explain what’s going on, and then I’ll drop the full thing at the end so it’s easy to copy, paste, and modify.
First, we’ll add a shebang and the set -e directive. The shebang tells the system to use the bash language to process the script, and the set -e directive tells the script to immediately exit if any of the commands in it fail (return a non-zero status).
#!/bin/bash
set -eNext, we’re going to add commands to navigate to the app project, get the latest version, and make sure dependencies are up to date:
# Update to latest version of code
cd /home/<YOUR_USERNAME>/my_app
git fetch
git reset --hard origin/main
mix deps.get --only prodNext, we’ll add a couple of optional CI steps, like running tests or enforcing code style with Credo. Even though it makes the build process a little slower, we’ll include the tests to at least make sure we can’t deploy code that’s breaking tests:
# Optional CI steps
mix test
# mix credo --strict (commented out, just another example step)We’ve got a little problem though: with our secure database password in place on the server, mix test will fail because it won’t be able to connect. To fix this, let’s update the mix test line to say CI=true mix test, and then save and quit so we can get out of the server and back to our local environment. We need to make a couple of code changes locally to support running tests on the server with the prod DB password. First, we’ll create a file config/test.secret.exs with the following content:
Use scp to copy the test.secret.exs file up to the server like we did with the prod secrets file in step 11.
Then, in your config/test.exs file, put the following at the very bottom, so that it pulls in the secret file only if the CI environment variable exists (like it does when the deploy script runs CI=true mix test):
if System.get_env("CI") do
import_config "test.secret.exs"
endCommit and push the change locally, and then get back on the server with ssh my_app. You’ll need to run git pull in the my_app directory to get the change.
Alright, run
vim deploy.shin the home directory on the server and we’ll keep going.
Next, we’ll add instructions to compile the app and static assets, setting the MIX_ENV variable to prod so we don’t have to specify it on the rest of the mix commands in the script:
# Set mix_env so subsequent mix steps don't need to specify it
export MIX_ENV=prod# Build phase
mix assets.deploy
Next, the script will check to see which release is up and running, e.g. the most recent release, by looking at all of the folder names in /releases (with ls), and since they’re all integers we can sort them numerically (-n) in reverse (-r, “descending”) and grab the first one (head). We use the unix pipe operator | to use the outputs and put them into the next function seamlessly, much like the Elixir pipe operator |>.
# Identify the currently running release
current_release=$(ls ../releases | sort -nr | head -n 1)
now_in_unix_seconds=$(date +'%s')
if [[ $current_release == '' ]]; then current_release=$now_in_unix_seconds; fiNext, the script will create the release, and place it in a folder named with the current time in unix, so each release will be timestamped which makes it easier for us to have an automated rollback script.
# Create release
mix release --path ../releases/${now_in_unix_seconds}Next, we’ll grab the value of the HTTP_PORT variable from the environment variable in the current release, which is the port number the currently running app is using (either 4000 or 4001). We’ll stuff those values in variables so we can switch the port forwarding later in the script.
# Get the HTTP_PORT variable from the currently running release
source ../releases/${current_release}/releases/0.1.0/env.shif [[ $HTTP_PORT == '4000' ]]
then
http=4001
https=4041
old_port=4000
else
http=4000
https=4040
old_port=4001
fi
Next, we need to update the env.sh file located deep in the folder structure of the release. When the release boots, it recognizes any environment variables stored in <release_name>/releases/<version_number>/env.sh. So, we shovel the environment variables into the file, and the release will pick them up when it starts. Here, we’re setting the ports the app will run on, which will be the ones that aren’t currently in use by the running app so we can cut over the port forwarding to the new ones.
# Put env vars with the ports to forward to, and set non-conflicting node name
echo "export HTTP_PORT=${http}" >> ../releases/${now_in_unix_seconds}/releases/0.1.0/env.sh
echo "export HTTPS_PORT=${https}" >> ../releases/${now_in_unix_seconds}/releases/0.1.0/env.sh
echo "export RELEASE_NAME=${http}" >> ../releases/${now_in_unix_seconds}/releases/0.1.0/env.shIn the section above, we’re also setting a
RELEASE_NAMEenvironment variable which sets the name of the node when Erlang boots up. We can’t have two nodes with the same name running simultaneously, so we just set the node name to the same value as the open port to avoid conflicts.
Next, we need to store the name of our new release in a file:
# Set the release to the new version
rm ../env_vars || true
touch ../env_vars
echo "RELEASE=${now_in_unix_seconds}" >> ../env_varsAnd run migrations:
# Run migrations
mix ecto.migrateNext, the script will use systemctl to start the app on the open port, and then it will use curl to ping the port every second till it’s alive before the script will continue.
# Boot the new version of the app
sudo systemctl start my_app@${http}# Wait for the new version to boot
until $(curl --output /dev/null --silent --head --fail localhost:${http}); do
echo 'Waiting for app to boot...'
sleep 1
done
Next, the moment of truth, the script will use those magic iptables commands (with the -R “Replace” option) to start forwarding to the ports that the new app is listening on.
# Switch forwarding of ports 443 and 80 to the ones the new app is listening on
sudo iptables -t nat -R PREROUTING 1 -p tcp --dport 80 -j REDIRECT --to-port ${http}
sudo iptables -t nat -R PREROUTING 2 -p tcp --dport 443 -j REDIRECT --to-port ${https}Finally, the script will clean up a bit by having systemctl shut down the previous version of the app. It all happens gracefully — requests in flight will finish before the old version is fully down:
# Stop the old version
sudo systemctl stop my_app@${old_port}# Just in case the old version was started by systemd after a server
# reboot, also stop the server_reboot version
sudo systemctl stop my_app@server_rebootecho 'Deployed!'
Whew, we made it!! Lots of command line tools in there like sort and ls and iptables, controlling systemd services with systemctl, and some bash concepts like variables and conditionals. Read more about systemd here, and bash scripts here if you want to get a little more context on these tools. Here’s the file all together:
This file might feel long or intimidating, but there’s a lot of power and flexibility in the approach. By using a single script to deploy, you’ll know exactly where to go if you want to add any custom steps or adjust things. Want to add more robust logic so that if the app doesn’t start up within some number of seconds, it kills the deploy? Just tweak the pause section. Want to add some static analysis? Great, add it to the CI section. Want to run it without migrations or without tests/CI? Just make a copy with a different name, take out the sections that don’t need to run and voilá! You’re working with the raw tools, so you won’t need to learn a framework or hack around constraints when you do need something custom.
Save and quit, then make the file executable:
chmod u+x deploy.sh15 — Create systemd services
Before we can actually run our deploy script, we need to create a systemd service that starts up the app (which basically just starts the release like <release_name>/bin/my_app start). The deploy.sh script we just created expects this service to be available — it calls it when it says sudo systemctl start my_app@${http}.
The reason we need a systemd service to run that command, instead of just having the deploy script run it, is so that if the app ever exits unexpectedly (for example, if your app runs out of memory or atoms and the BEAM crashes), systemd will notice and boot the app again in a clean state.
Within your Elixir app, you have a supervision tree to manage and monitor when processes crash and reset them — you can think about
systemdlike it’s the supervisor for your supervision tree.
There’s another bonus — by having a systemd service start the app, the logs that the app produces will be piped out to journald automatically, which makes it easy to attach to the stream when you want to and it’s also a very standard log interface so it’s easy to connect to third-party logging services.
Let’s go ahead and create a new systemd service:
sudo vim /etc/systemd/system/my_app@.serviceAdd the following contents (swapping in your own username):
The most significant lines for us are 12 and 14. First, we pull in the env_vars file we created in the last step, which tells the service what folder the latest release is in, and then on line 14 we actually start the release.
The name of this service file is important: adding the
@makes it a “template”, which means that we can run it multiple times with different values after the@which in our case will be4000and4001. This enables us to have two instances of the app running at the same time so that we can gracefully switch theiptablesforwarding rules to the new ports, before the old app is shut down. You can read more about running multiple instances of asystemdservice here.
Now, let’s enable the service so that if the server is restarted, systemd knows to start back up the most recent version of the app:
sudo systemctl enable my_app@server_rebootAnd now reload systemd to make sure our changes are available (you’ll need to do this any time you modify the systemd service):
sudo systemctl daemon-reloadOne last thing before we’re done here: we need a way for our app to know at runtime which port to use, but at the point in our deploy script where the available port is discovered, the release has already been built and all of the config has been set at compile time. Release runtime configuration to the rescue! Locally in your project (back on your dev machine), add the following to your config/runtime.exs file:
Commit and push that change so it’s available on your server as well.
16 — Deploy the app
We’ve come a long way and done a lot of work! We’re finally ready for that sweet sweet payout: running the deploy script and watching the app come to life.
One of the cool things about
sshis that you can use it to run a command in your local terminal, but have it execute on the server. Let’s do that. In your local terminal, run the following command:
ssh my_app ./deploy.shYou’ll see some output as the script works through the various build, CI, release, and booting steps. If all goes well, you should be able to visit <your_domain>.com and see the app running!
To really see the magic, commit and push a change locally and then run the command again, and you’ll see it gracefully swap over to the new version without any downtime 🎉🎉🎉.
If you’d like to see the Phoenix live dashboard, just add :prod to the list with [:dev, :test] at the bottom of your router.ex and deploy the app again.
17 — Attach to journald to watch logs, and configure to trim
Logs aren’t the most exciting part of building an app, but you’ll be grateful for them when you’re troubleshooting tough bugs. Because the deploy script uses a systemd service to actually run the command to start the release, standard output is routed to journald which stores the logs.
Just like we used
systemctlto start and stopsystemdservices, we use a utility calledjournalctlto query and manipulatejournaldlogs. If you want a deep dive, you can read up here, here, or here. I’ll just show you a couple of useful commands, to help you get a window into your logs as the app is running in real time, butjournalctlsupports a wide variety of querying for more advanced uses.
To attach to the journal and “follow” it (basically, as logs come in you see them update in real time), run the following command locally:
ssh my_app journalctl -fNow, if you visit <your_domain>.com a few times, you’ll see some logs show up in your terminal. Sweet!
You can also print out the most recent n logs, with the following command:
ssh my_app journalctl -n 500You may see some logs in there that don’t have to do with your app — to limit it to just your app you can run this:
ssh my_app journalctl -n 50 -u my_app@4001Adding the -u my_app@<PORT> limits it to just that “unit”. Your app will always be running on either 4000 or 4001, so if the most recent log for the port you picked looks like the following, try the other one to see the output for the running app.
Nov 03 21:43:33 instance-1 systemd[1]: Stopped My App.One more thing before we stop talking about logs: let’s update the journald config so that it starts trimming logs at 4GB so that logs don’t eventually consume all available disk space. ssh my_app to get on the server, then run sudo vim /etc/systemd/journald.conf to edit the config file. Find the line that has SystemMaxUse, uncomment it, and add 4G to the end like this:
SystemMaxUse=4GSave and quit, and then restart journald like this:
sudo systemctl restart systemd-journald.serviceYou made it! 🙌
Congratulations, you’re now armed with a fully loaded Phoenix app running on free hardware without the compromises. You can deploy new versions of your code with a single command, achieve zero-downtime deploys without hot code reloading, and tap into the database and logs from your development machine with ease.
I’ve included a few bonus sections if any of them spark your interest. Thanks for reading, and please reach out to me at damonvjanis@gmail.com if you have any questions or comments.
Bonus 1: secure your data against the possibility of eventual hardware failure by creating another Google account with a free instance and set up automated backups using cron
I’m not going to go into exhaustive detail here, and this is not a sophisticated approach, but it can be a starting point.
Follow steps 2–5 of the guide again but with a new Google account, and instead of my_app name your alias something like backups. Now that you’ve got your server up and running and you can connect to it, install Postgres:
sudo apt install postgresql postgresql-contribNow hit cd to make sure you’re in the home directory, and enter vim .pgpass to create a password file for Postgres. Put the following contents in it, using the values from the server you set up for my_app:
#hostname:port:database:username:password
<server IP address>:5432:my_app:postgres:<postgres password>Now hit chmod 600 ./.pgpass to give the file correct permissions.
Open the cron configuration file by running crontab -e, then at the bottom of the file add the following:
Since the chron job sill be writing to a folder called /my_app/ in your home directory, we need to create it: mkdir my_app.
To make sure that the chron job actually works, instead of waiting an hour for it to run, try running the pg_dump task like the job does:
pg_dump -U postgres -h <server IP address> -p 5432 my_app > ~/my_app/my_app_hourly.bakIf all goes well, you should see a new folder my_app/ with a backup inside. Sweet!
You can learn more about cron here.
Bonus 2: Rollback script
Here’s a rollback script, you can put it in your home directory on the server next to deploy.sh and run it the same way: ssh my_app ./rollback.sh.
Save and quit, then make the file executable:
chmod u+x rollback.shNote: you’ll need to handle rolling back database migrations manually, by running MIX_ENV=prod mix ecto.rollback within the app directory on the server, if you need to roll back a migration.
The script will boot up the previous release, and if you need to go back more than one just keep running the script. It’s fast — it only takes a few seconds before the last release is the one running in prod!
And that’s a wrap! Thanks for reading 🙏
Update, June 2, 2021: Ruslan Kenzhebekov emailed me and pointed me to a comment thread he’d had with Sasa Juric (the author of the Site Encrypt library) where Sasa mentioned that he used iptables switching to achieve zero-downtime deployments without nginx or a reverse proxy. That prompted me to learn (a lot!) and update this article as a result. You can still find the old version here if you prefer it.
I’ve updated this article and hopefully simplified/improved it from the previous approach. The major change is that instead of using the Nginx web server as a reverse proxy and Certbot for SSL, we’re using the built-in Cowboy web server and the Elixir SiteEncrypt library for SSL. This helps eliminate some external dependencies and keeps our concerns focused squarely on Elixir. I also refined a few sections and simplified the deployment/rollback scripts and fixed some bugs in them.
Update, March 30, 2023: I’ve gone through the guide again to make sure it still works as of Phoenix version 1.7 (which requires Elixir 1.14). I’ve also updated the example repo since Elixir/Phoenix config has changed a lot since I first wrote the guide. The biggest hurdle right now is that Elixir 1.14 isn’t available through the apt package manager, so you’ll have to use an alternative installation like asdf or kiex in the meantime.